publications
2025
-
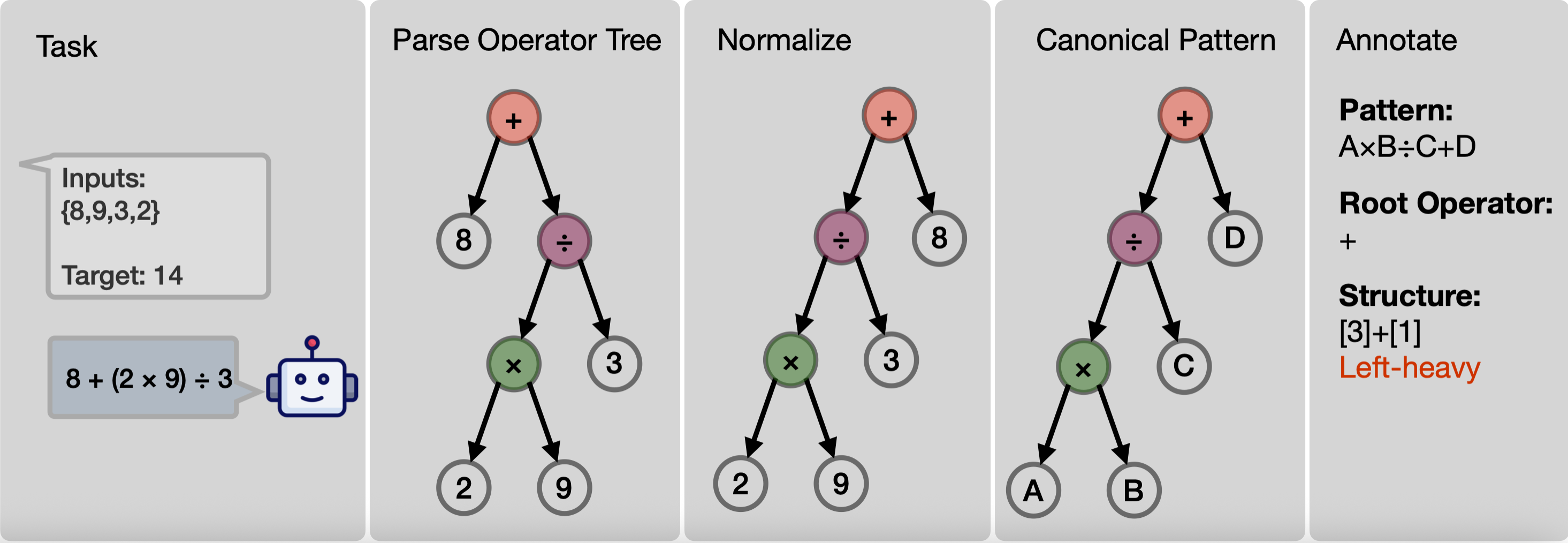 How Does RL Post-training Induce Skill Composition? A Case Study on CountdownSimon Park*, Simran Kaur*, and Sanjeev AroraEfficient Reasoning Workshop at NeurIPS 2025 (Spotlight)), 2025
How Does RL Post-training Induce Skill Composition? A Case Study on CountdownSimon Park*, Simran Kaur*, and Sanjeev AroraEfficient Reasoning Workshop at NeurIPS 2025 (Spotlight)), 2025While reinforcement learning (RL) successfully enhances reasoning in large language models, its role in fostering compositional generalization (the ability to synthesize novel skills from known components) is often conflated with mere length generalization. To this end, we study what RL post-training teaches about skill composition and how the structure of the composition affects the skill transfer. We focus on the Countdown task (given n numbers and a target, form an expression that evaluates to the target) and analyze model solutions as expression trees, where each subtree corresponds to a reusable subtask and thus can be viewed as a “skill.” Tracking tree shapes and their success rates over training, we find: (i) out-of-distribution (OOD) generalization to larger n and to unseen tree shapes, indicating compositional reuse of subtasks; (ii) a structure-dependent hierarchy of learnability – models master shallow balanced trees (workload is balanced between subtasks) before deep unbalanced ones, with persistent fragility on right-heavy structures (even when the composition depth is the same as some left-heavy structures). Our diagnostic reveals what is learned, in what order, and where generalization fails, clarifying how RL-only post-training induces OOD generalization beyond what standard metrics such as pass@k reveal.
-
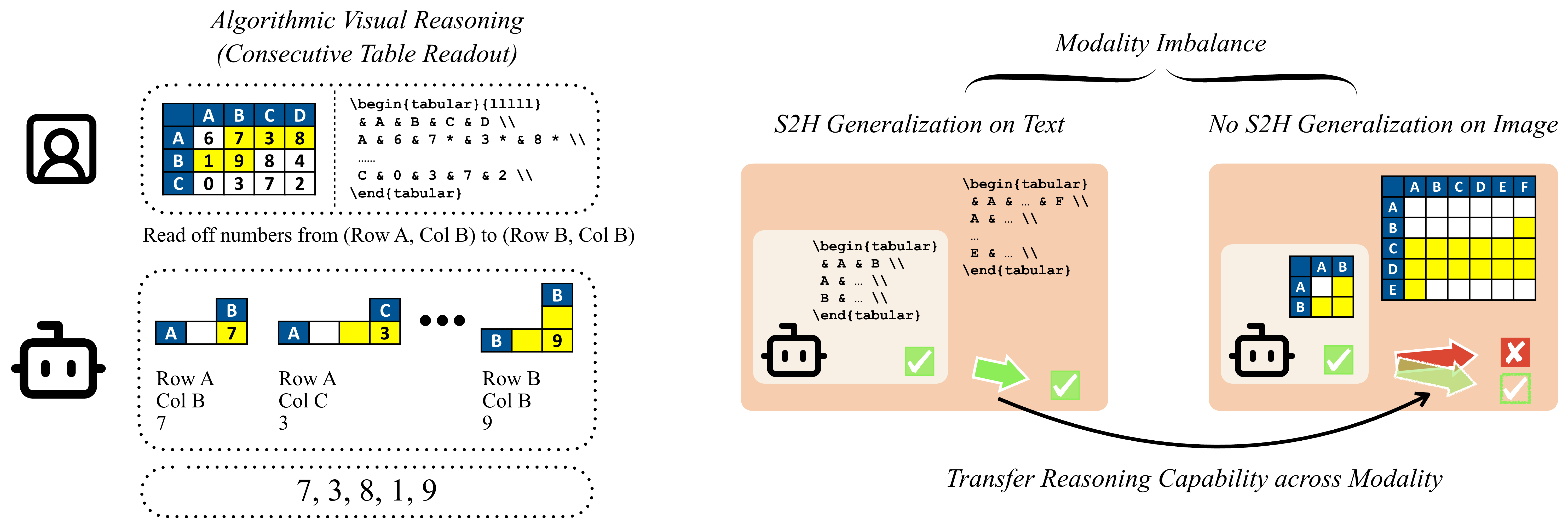 Generalizing from SIMPLE to HARD Visual Reasoning: Can We Mitigate Modality Imbalance in VLMs?Simon Park*, Abhishek Panigrahi*, Yun Cheng*, Dingli Yu, Anirudh Goyal, and 1 more authorICML 2025, 2025
Generalizing from SIMPLE to HARD Visual Reasoning: Can We Mitigate Modality Imbalance in VLMs?Simon Park*, Abhishek Panigrahi*, Yun Cheng*, Dingli Yu, Anirudh Goyal, and 1 more authorICML 2025, 2025While Vision Language Models (VLMs) are impressive in tasks such as visual question answering (VQA) and image captioning, their ability to apply multi-step reasoning to images has lagged, giving rise to perceptions of modality imbalance or brittleness. Towards systematic study of such issues, we introduce a synthetic framework for assessing the ability of VLMs to perform algorithmic visual reasoning (AVR), comprising three tasks: Table Readout, Grid Navigation, and Visual Analogy. Each has two levels of difficulty, SIMPLE and HARD, and even the SIMPLE versions are difficult for frontier VLMs. We seek strategies for training on the SIMPLE version of the tasks that improve performance on the corresponding HARD task, i.e., S2H generalization. This synthetic framework, where each task also has a text-only version, allows a quantification of the modality imbalance, and how it is impacted by training strategy. Ablations highlight the importance of explicit image-to-text conversion in promoting S2H generalization when using auto-regressive training. We also report results of mechanistic study of this phenomenon, including a measure of gradient alignment that seems to identify training strategies that promote better S2H generalization.
2024
-
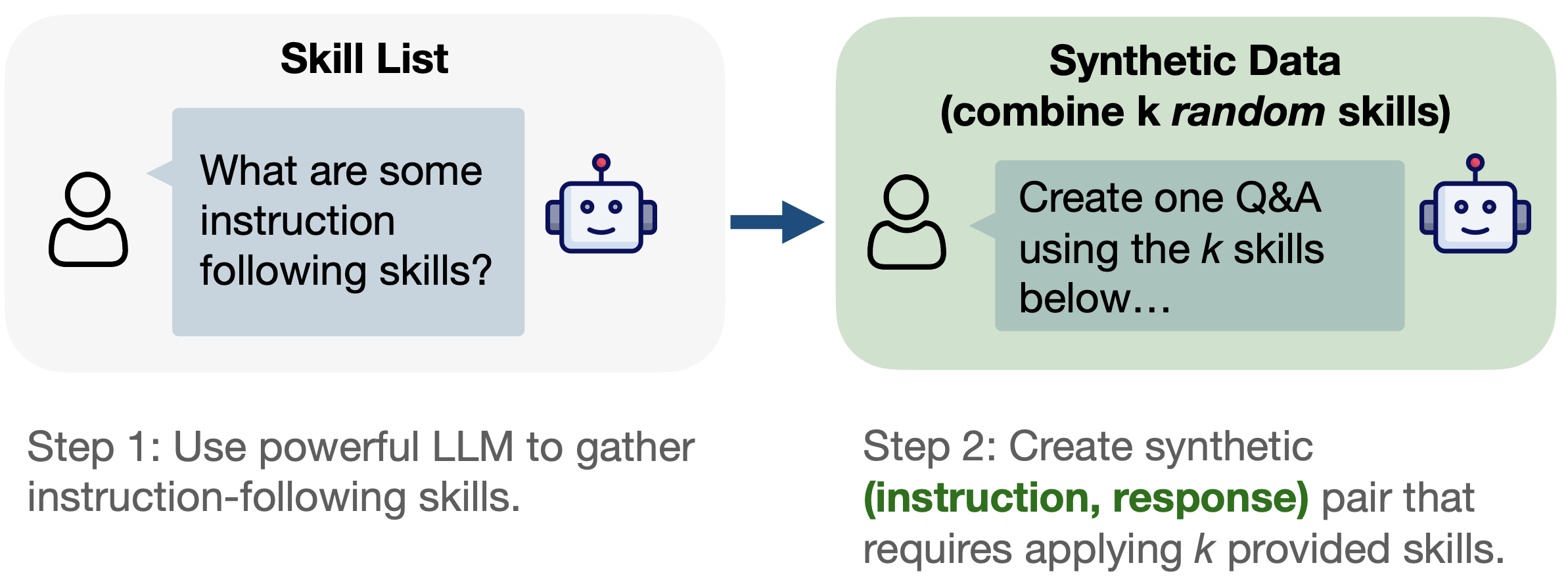 Instruct-SkillMix: A Powerful Pipeline for LLM Instruction TuningSimran Kaur*, Simon Park*, Anirudh Goyal, and Sanjeev AroraICLR 2025, 2024
Instruct-SkillMix: A Powerful Pipeline for LLM Instruction TuningSimran Kaur*, Simon Park*, Anirudh Goyal, and Sanjeev AroraICLR 2025, 2024We introduce Instruct-SkillMix, an automated approach for creating diverse, high quality SFT data. The Instruct-SkillMix pipeline involves two stages, each leveraging an existing powerful LLM: (1) Skill extraction: uses the LLM to extract core "skills" for instruction-following, either from existing datasets, or by directly prompting the model; (2) Data generation: uses the powerful LLM to generate (instruction, response) data that exhibit a randomly chosen pair of these skills. Here, the use of random skill combinations promotes diversity and difficulty. Vanilla SFT (i.e., no PPO, DPO, or RL methods) on data generated from Instruct-SkillMix leads to strong gains on instruction following benchmarks such as AlpacaEval 2.0, MT-Bench, and WildBench. With just 4K examples, LLaMA-3-8B-Base achieves 42.76% length-controlled win rate on AlpacaEval 2.0. To our knowledge, this achieves state-of-the-art performance among all models that have only undergone SFT (no RL methods) and competes with proprietary models such as Claude 3 Opus and LLaMA-3.1-405B-Instruct. Ablation studies also suggest plausible reasons for why creating open instruction-tuning datasets via naive crowd-sourcing has proved difficult. Introducing low quality answers ("shirkers") in 20% of Instruct-SkillMix examples causes performance to plummet, sometimes catastrophically. The Instruct-SkillMix pipeline is flexible and is adaptable to other settings.
-
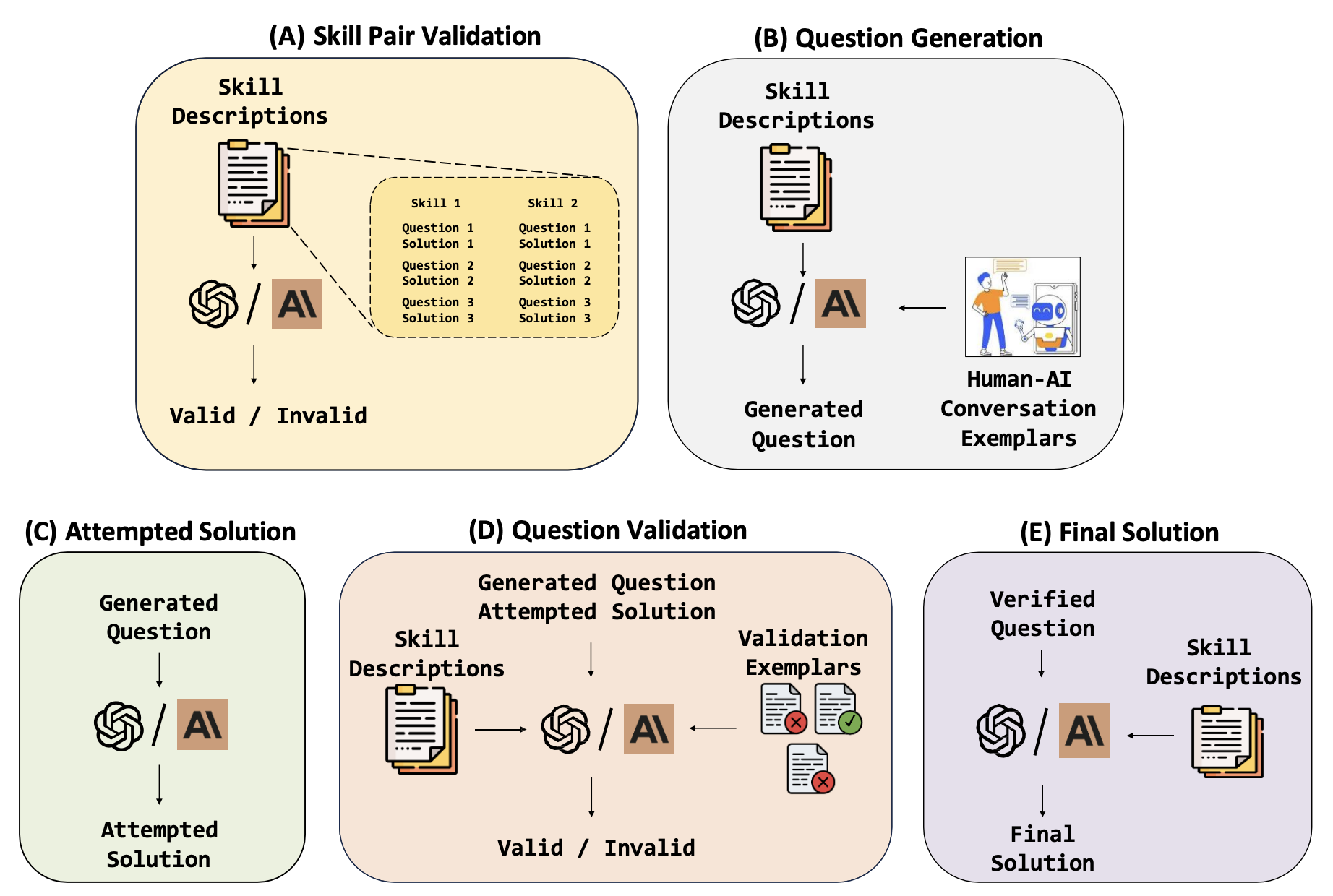 AI-Assisted Generation of Difficult Math QuestionsVedant Shah, Dingli Yu, Kaifeng Lyu, Simon Park, Jiatong Yu, and 6 more authorsMath-AI Workshop at NeurIPS 2024, 2024
AI-Assisted Generation of Difficult Math QuestionsVedant Shah, Dingli Yu, Kaifeng Lyu, Simon Park, Jiatong Yu, and 6 more authorsMath-AI Workshop at NeurIPS 2024, 2024Current LLM training positions mathematical reasoning as a core capability. With publicly available sources fully tapped, there is unmet demand for diverse and challenging math questions. Relying solely on human experts is both time-consuming and costly, while LLM-generated questions often lack the requisite diversity and difficulty. We present a design framework that combines the strengths of LLMs with a human-in-the-loop approach to generate a diverse array of challenging math questions. We leverage LLM metacognition skills [Didolkar et al., 2024] of a strong LLM to extract core "skills" from existing math datasets. These skills serve as the basis for generating novel and difficult questions by prompting the LLM with random pairs of core skills. The use of two different skills within each question makes finding such questions an "out of distribution" task for both LLMs and humans. Our pipeline employs LLMs to iteratively generate and refine questions and solutions through multiturn prompting. Human annotators then verify and further refine the questions, with their efficiency enhanced via further LLM interactions. Applying this pipeline on skills extracted from the MATH dataset [Hendrycks et al., 2021] resulted in MATH2 - a dataset of higher-quality math questions, as evidenced by: (a) Lower performance of all models on MATH2 than on MATH (b) Higher performance on MATH when using MATH2 questions as in-context examples. Although focused on mathematics, our methodology seems applicable to other domains requiring structured reasoning, and potentially as a component of scalable oversight. Also of interest is a striking relationship observed between models’ performance on the new dataset: the success rate on MATH2 is the square on MATH, suggesting that successfully solving the question in MATH2 requires a nontrivial combination of two distinct math skills.
2023
-
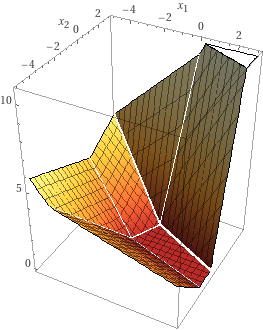 Infinite-Width 1-Layer ReLU Networks with L2 Regularization on 2D DataSimon Park2023
Infinite-Width 1-Layer ReLU Networks with L2 Regularization on 2D DataSimon Park2023Given a dataset D = ((x_1^(i) ,x_2^(i)), y^(i)) of two-dimensional input and one-dimensional output, we investigate the set of 1-layer ReLU networks f(x; θ) that interpolate the dataset and, among such interpolants, minimize the L2 norm of the weights. In Section 3.1, we consider a dataset D where the points x^(i) = (x_1^(i), x_2^(i)) form the vertices of a regular polygon. We present the optimal network that assigns a non-zero value to one or two consecutive points on the polygon. Using this as a basic component, we present a heuristic of constructing an interpolant f of the dataset D which we believe to be near-optimal. In Section 3.2, we consider D to be symmetric with respect to a line L. We show that if the dataset is effectively 1-dimensional, then any optimal f should also be 1-dimensional.
2022
-
 Introduction to Machine Learning: Lecture Notes for COS324 at Princeton UniversitySanjeev Arora, Simon Park, Dennis Jacob, and Danqi Chen2022
Introduction to Machine Learning: Lecture Notes for COS324 at Princeton UniversitySanjeev Arora, Simon Park, Dennis Jacob, and Danqi Chen2022