AI-Assisted Generation of Difficult Math Questions
Vedant Shah, Dingli Yu, Kaifeng Lyu, Simon Park, Jiatong Yu, and 6 more authors
Math-AI Workshop at NeurIPS 2024, 2024
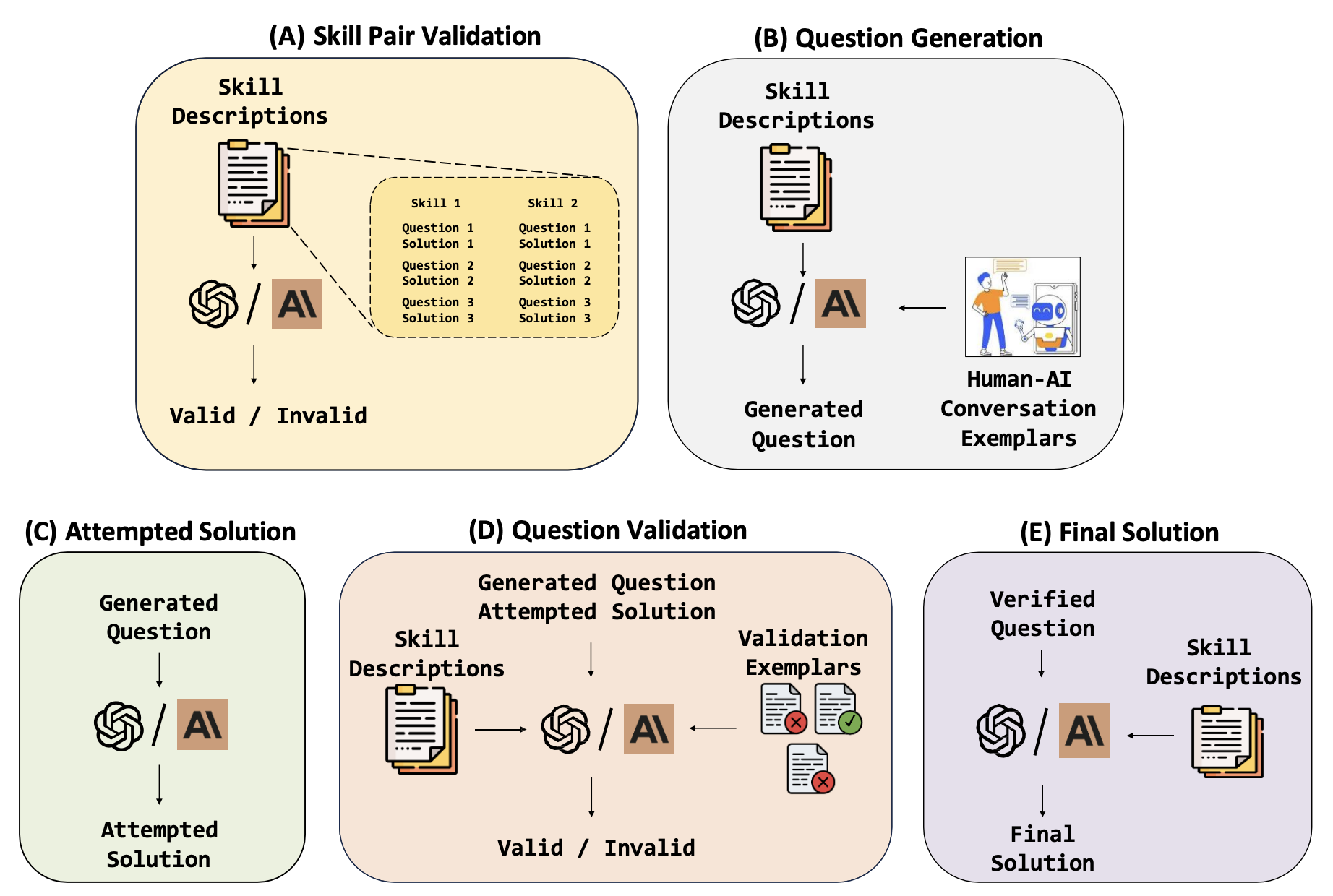
Current LLM training positions mathematical reasoning as a core capability. With publicly available sources fully tapped, there is unmet demand for diverse and challenging math questions. Relying solely on human experts is both time-consuming and costly, while LLM-generated questions often lack the requisite diversity and difficulty. We present a design framework that combines the strengths of LLMs with a human-in-the-loop approach to generate a diverse array of challenging math questions. We leverage LLM metacognition skills [Didolkar et al., 2024] of a strong LLM to extract core "skills" from existing math datasets. These skills serve as the basis for generating novel and difficult questions by prompting the LLM with random pairs of core skills. The use of two different skills within each question makes finding such questions an "out of distribution" task for both LLMs and humans. Our pipeline employs LLMs to iteratively generate and refine questions and solutions through multiturn prompting. Human annotators then verify and further refine the questions, with their efficiency enhanced via further LLM interactions. Applying this pipeline on skills extracted from the MATH dataset [Hendrycks et al., 2021] resulted in MATH2 - a dataset of higher-quality math questions, as evidenced by: (a) Lower performance of all models on MATH2 than on MATH (b) Higher performance on MATH when using MATH2 questions as in-context examples. Although focused on mathematics, our methodology seems applicable to other domains requiring structured reasoning, and potentially as a component of scalable oversight. Also of interest is a striking relationship observed between models’ performance on the new dataset: the success rate on MATH2 is the square on MATH, suggesting that successfully solving the question in MATH2 requires a nontrivial combination of two distinct math skills.